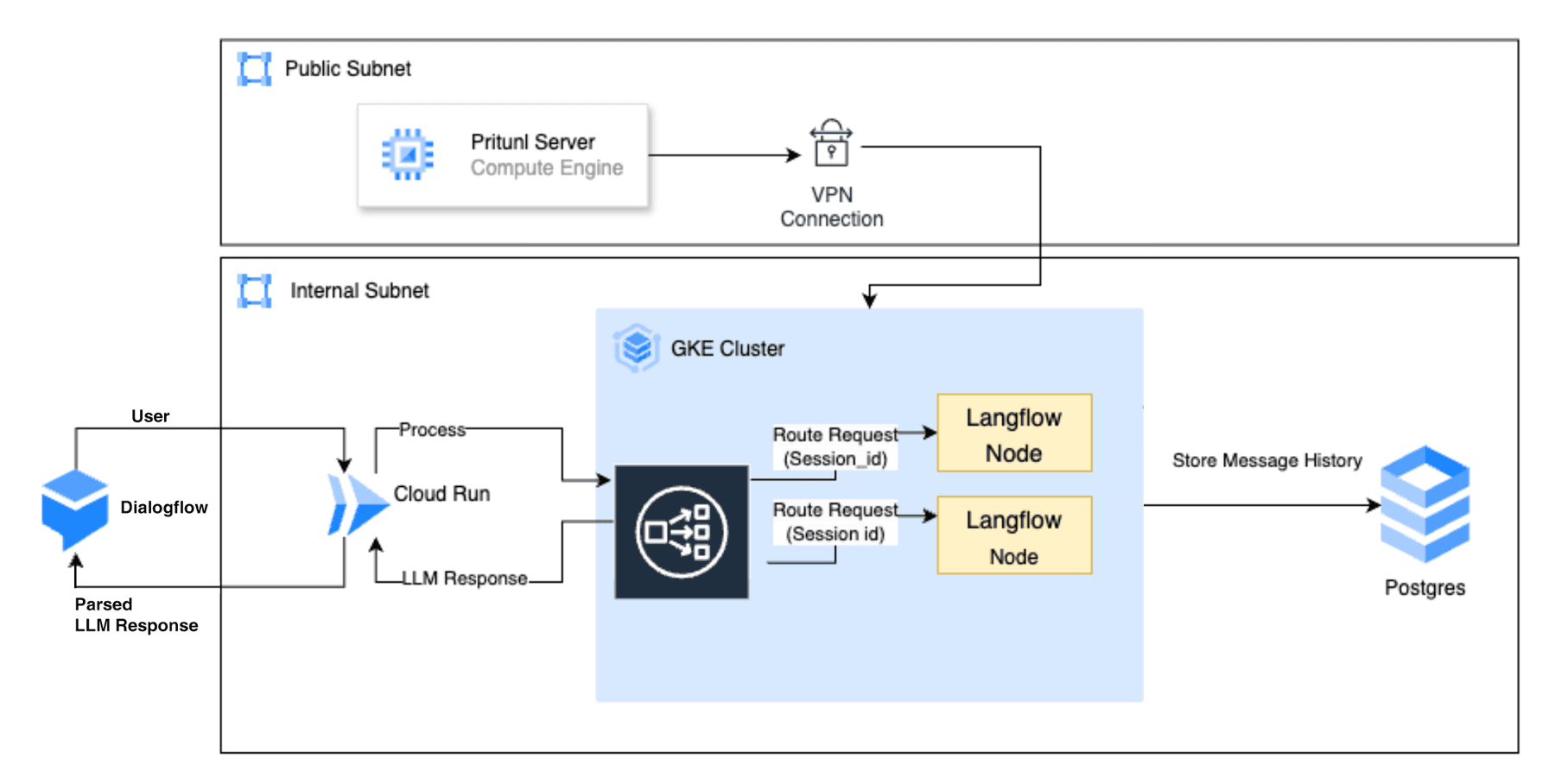
VM based Architecture
Frequent downtime, no automated scaling, manual maintenance overhead.

High Memory Usage
Langflow runtime steadily consumed over 2 GB of memory, eventually leading to system crashes.

PostgreSQL Deadlocks
100% of requests started failing under load testing conditions.

Slow Response Times
Chat responses took 30-40 seconds under typical concurrency.

Low Concurrent Capacity
The system could reliably handle only ~50 concurrent users.

Public Exposure Risk
Endpoints were publicly accessible with no unified access control.