

We had been discussing the necessities of indefinite storage scaling ( Part -1 ), basic concept of CEPH (Part -2 ) and its technical design and implementation process ( Part -3 ) through the last few blogs. Now let us have a detailed look into the working of the system ie how Ceph manages data storage using CRUSH
How CEPH Stores and Manages Data in RADOS?
The answer to this question is quite simple, the CRUSH algorithm . Unlike all other distributed file systems that use a centralized registry/server holding all the information on the data storage architecture to be stored, Ceph uses an algorithm.
Earlier, data or objects were placed to a storage pool using the information from a metadata server. ie; a metadata server holds the information on how and where to place/retrieve data from a storage location. But this architecture had a one point failure, where the metadata server crashes.
To re-stabilize the architecture, manual configurations were necessary, or we can say that the architecture is not a self healing one. Also, the metadata server needs to hold a large amount of information about the data/object if the storage cluster is infinitely big and changing. So using a metadata server in an infinitely big and changing distributed storage system is not reliable.
This is one among the area where Ceph has an advantage over all other distributed storage architectures. It is a self managing, self healing architecture. As mentioned before this is obtained using CRUSH Algorithm.
CRUSH – Controlled Replication Under Scalable Hashing
CRUSH is an algorithm that Ceph clients use to place its objects in the RADOS Storage Cluster. The algorithm is Pseudo-random with fast calculations and no central lookups.
Working
If there is a bunch of bits/objects that needs to be stored in the Ceph Storage Cluster, Ceph client first hashes the object name and splits it into a number of Placement Groups(pg’s). Placement groups are just split based on names.
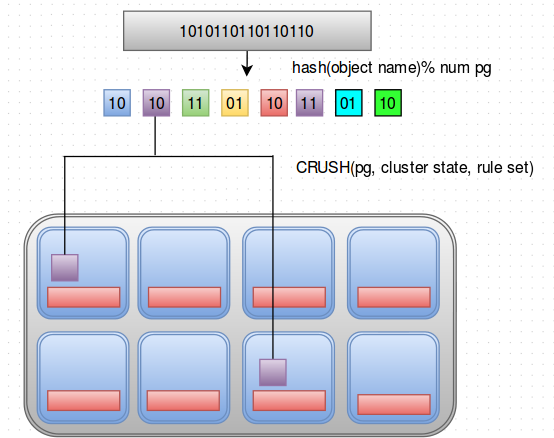
Now, the Ceph client knows in which pg the object belongs to. Then CRUSH Algorithm is called on each of these pg’s along with the Cluster State and a Rule Set which it gets from Ceph Monitors available in the Cluster. And based on this CRUSH does some calculations on where to put the object in the cluster. The calculation takes place by its own and also at a very high speed. So there is no need for any another dedicated server/application to tell Ceph where to put the object in the cluster. Rather, CEPH clients calculates it using the cluster state and rule set which it receives from the monitors.
Then CRUSH statistically and evenly distributes the objects into different OSD’s available in the cluster.
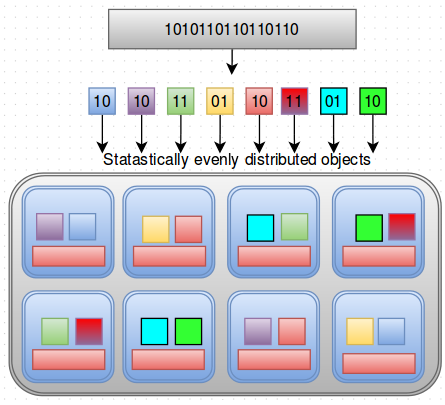
- Pseudo-random object placement algorithm
- Fast calculations and no lookups.
- Repeatable- If you give the same information to crush it gives the same result/output always.
- Statistically distributes data evenly in the cluster.
- Limited data/object migration on any change to the cluster state. ie; if any OSD is down, limited amount of object are moved around in the cluster.
If a client requests an object from the cluster, it will calculate the pg and call CRUSH and CRUSH tells which OSD’s to look into and where to find it. It tells where your data is in the RADOS cluster as shown in the diagram below.
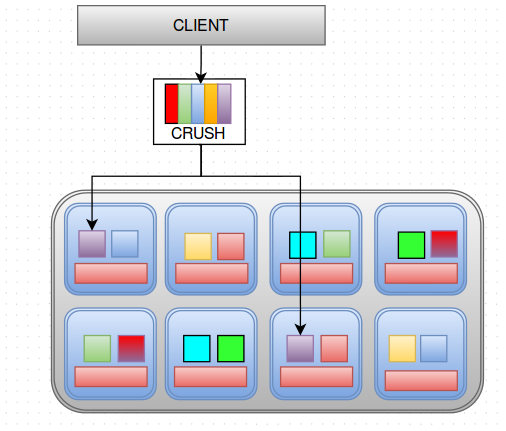
This is done using some calculations that CRUSH uses as I mentioned before. A detailed look into the calculation is described below.
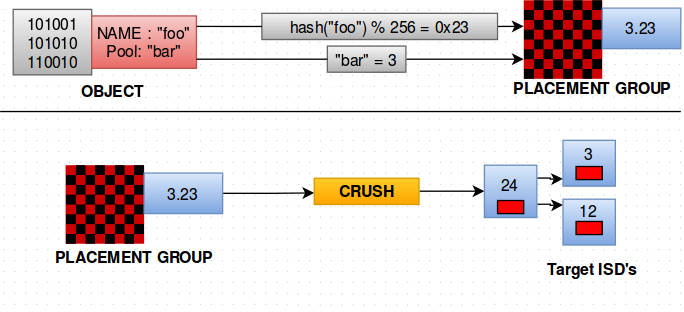 Illustration
Illustration
Let us consider an object Named “foo” and having Pool “bar”. The client first hashes the object name foo into number of pg’s. So hash (“foo”) % 256 =0x23. So the hash value of object name is 23. Now it takes the Pool number from the Object and its 3 here. So pg =pool.hash=3.23. Then the pg value 3.23 is passed to the CRUSH algorithm and it tells the client the target OSD’s. All these calculations are done on the client side. CRUSH is called by the client after it calculates the pg value.
Now lets see how the replication happens when an OSD goes down. In the diagram given blow, consider the OSD labeled DOWN to be Crashed/Down. It had two objects- Yellow and Blue. So from a total of 8 nodes one is down.
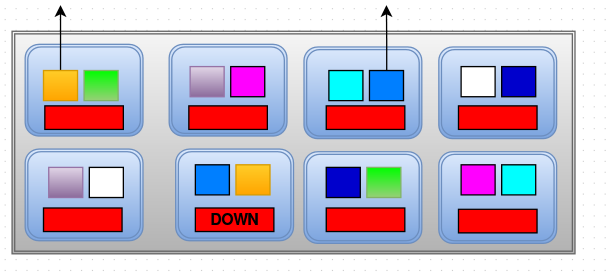 OSD’s communicate with each other in a peer to peer fashion constantly. They will also have the cluster map obtained from the Monitors. When the node failed/crashed, Monitors provided a new cluster map to the OSD’s. And thus, the OSD’s became aware that one of the OSD is down and it starts to replicate it to other available OSD in a peer to peer fashion. With the new cluster map and new calculations, OSD’s know which host/node has the object copy of the missing OSD and where(on which OSD) to put the objects of the missing OSD. And it replicates the object to the new OSD as shown in the diagram below and the cluster re-balances.
OSD’s communicate with each other in a peer to peer fashion constantly. They will also have the cluster map obtained from the Monitors. When the node failed/crashed, Monitors provided a new cluster map to the OSD’s. And thus, the OSD’s became aware that one of the OSD is down and it starts to replicate it to other available OSD in a peer to peer fashion. With the new cluster map and new calculations, OSD’s know which host/node has the object copy of the missing OSD and where(on which OSD) to put the objects of the missing OSD. And it replicates the object to the new OSD as shown in the diagram below and the cluster re-balances.
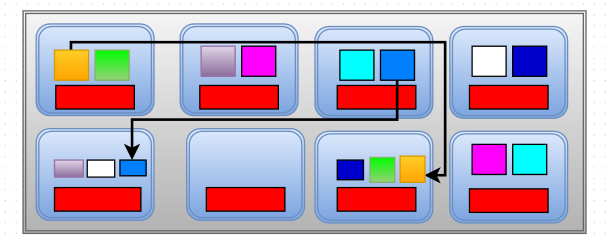
From here on, the new cluster map is maintained until the crashed OSD is replaced. If there are 100 nodes in a cluster and one node goes down, the replication/change in cluster is 1/100th of data, which is a small change. Thus if any OSD is down, only a limited amount of object are moved around in the cluster.
After all this the Ceph clients get the new cluster map. So when accessing objects, the client uses new hash values and gets the data correctly.
********
The diagrams and metaphors used are inspired by Inktank’s Vice president Ross Turk’s speech on introduction to CEPH
Previous Articles
Infinite Storage Scaling Using CEPH
CEPH – Part 2 – Philosophy and Design
CEPH – Part -3 – Technical Architecture and Components
Next Part of this document deals with the configuration of Ceph storage cluster on Ubuntu 14.04 trusty LTS.
![]()



